This blog post explores the data science work performed to build a crosswalk between ESCO and O*NET, the Occupational Information Network, developed by the U.S. Department of Labor/Employment and Training Administration (U.S. DOL).
In the past, crosswalks were created only sporadically, as they require a remarkable effort in terms of time and resources. Today, new technologies such as Machine Learning and Natural Language Processing significantly reduce the effort required to carry out such activities. The ESCO-O*NET crosswalk represents a first successful attempt to connect two international standards by combining the use of artificial intelligence (AI) techniques with human validation. Such synergy assured higher accuracy and consistency of the results, while reducing the manual effort in terms of working hours.
The following sections illustrate the methodology employed for this exercise, focusing on the work conducted by the ESCO data science team. We include performance statistics and details concerning our algorithms, with the aim to share know-how and support the implementation of ESCO in different and innovative applications.
Methodology: combining algorithms and human expertise in one pipeline
O*NET occupations were divided into three groups through stratified random sampling based on SOC groups. Each group was treated as a single batch of work. Batches were processed in different periods starting in mid-2021 and finishing in mid-2022.
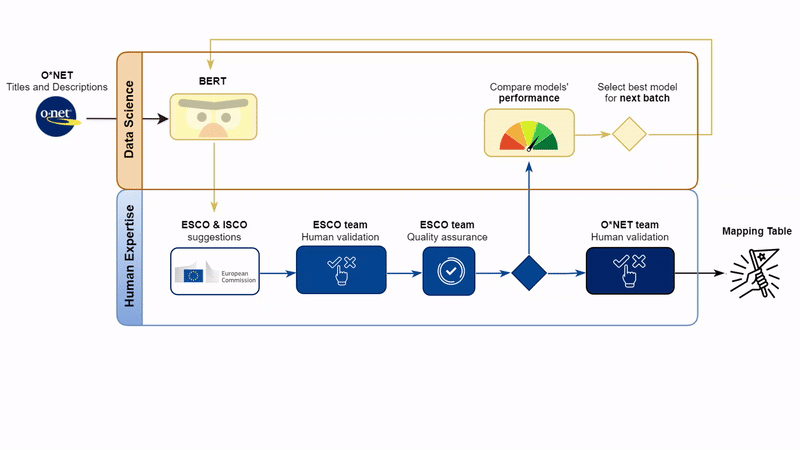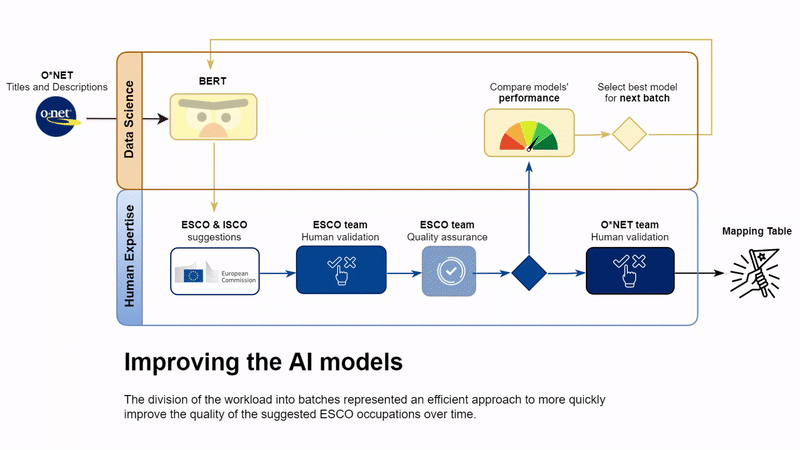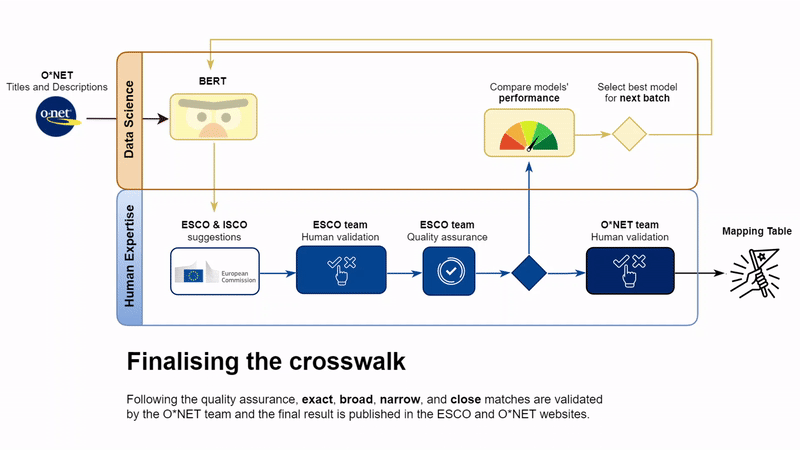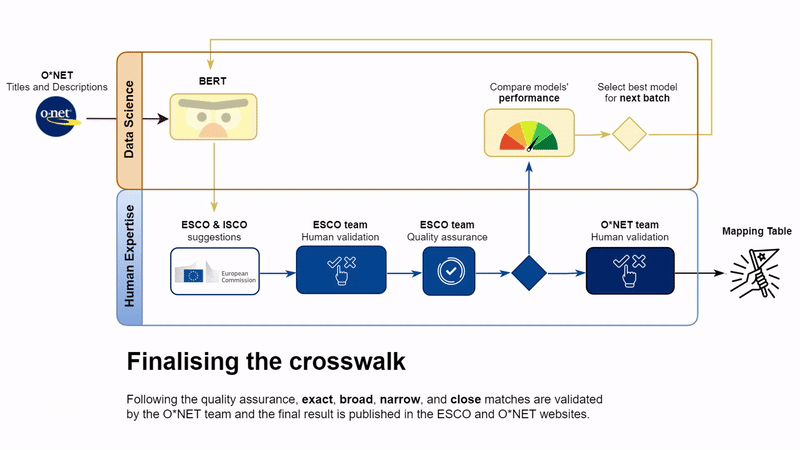
The first part of the pipeline followed a linear path, starting from the work of the ESCO data science team and followed by the validation by the whole ESCO team:
1. The European Commission developed AI models that match O*NET occupations (input) to ESCO occupations (output) based on semantic textual similarity. The models were trained using labour market expert feedback, national taxonomies, Qualification Data Register qualifications, and online job vacancies.
2. Based on the best-performing machine learning model, ten ESCO occupations were suggested for every O*NET occupation. These represented the ESCO occupations with the highest-ranking scores and were considered as semantically most similar to the respective O*NET occupation by the model.
3. The ESCO team proceeded with human validation: the occupations were equally distributed among the team members, who determined the relationship between each suggested O*NET-ESCO occupation pair. This was done following a pre-established set of rules which defined a range of possible relations between concepts and the detailed information about those concepts (i.e. descriptions, tasks, job titles, etc.).
4. Validations went through a quality assurance process, where a different validator checked the established relations and, in case of disagreement, a third validator was involved.
At this point, the pipeline is split in two parts.
One strand of work is reverted back to the data science team to compare the validations from one batch with the performance of different models. This allowed to select the best-performing model, hence improving the quality of the suggestions proposed to the validators and reduce the time required for the human work across different batches. The second strand of work concerns the collaboration with the U.S. DOL, where the colleagues further validated the results and improved the quality of the work thanks to their knowledge of the O*NET classification.
Following a final discussion among the two teams in case of disagreement on validations, the process is concluded. Merging the three batches, the crosswalk table is finalised and is now available at the Other Mapping Tables in the ESCO Portal.
The AI algorithms: comparing performances and improving the suggestions
To establish a crosswalk between the European and U.S. classification of occupations, the ESCO Data Science Team focused on developing an approach to detect the most semantically similar ESCO occupations for an O*NET occupation. Semantic similarity between occupation concepts is defined over the closeness at meaning or semantic level between O*NET job titles and descriptions, and ESCO preferred terms, alternative terms and descriptions. Semantic similarity plays a significant role in various natural language processing (NLP) tasks as it allows to assign a score, representing likeness of meaning, to the relationship between two textual items.
For the purpose of generating ESCO occupation suggestions, the approach was to apply transformer language models to encode definitions of occupations in embeddings and then to use the cosine similarity metric to compute a similarity score. Specific to this case, the Bidirectional Encoder Representations from Transformers (BERT) language model was fine-tuned by the team through multi-task learning while adding an additional linear layer to the original BERT model. Different strategies to optimise model performance (i.e. a model that, for one O*NET occupation, assigns the higher score to the most similar ESCO occupation) included using different optimisation methods, loss functions, combinations of the input information and training iterations.
Details on the AI models employed for the occupation mapping
The table above shows details of the models employed for the three batches, where Model 1 was adopted for the first batch of validation, and so forth. The performance of the three models is then compared in the graphics below, where we distinguish the accuracy of the suggestions between exact and exact, broad, narrow and close matches. These represent a range of mapping options available for validators and further explained in the Technical Report which can be downloaded at the end of this blog post.
The team gave priority to the model which could suggest the exact matches first in the ranking - being these defined as concepts in O*NET covering the same scope as concepts in ESCO and vice versa. Model 3 scored as the best-performing model, suggesting 85% of the exact matches as the first ESCO suggestion, with an additional increase to 90% when considering narrow, broad and close matches.
Results
The work presented in this post, together with the manual validation efforts, led to the publication of a crosswalk between the ESCO and O*NET classifications for occupations. All the ESCO occupations are mapped to at least one O*NET occupation, based on different types of relations (see the mapping guidelines in the Technical Report below). The range of relations eases the process of comparisons of the two classifications, which differ by number of concepts and granularity.
The crosswalk can be downloaded free of charge at this page. We publish two versions of the crosswalk: the first version includes exact, narrow, broad, and close matches. The second version has the same information as the first version, but it is also enriched with related matches. The latter type of relationship was not included in the quality assurance steps and was not included in the validation process run by the U.S. DOL, hence it must be considered as data of lower quality. We share the second version to provide additional training and testing material to ESCO implementers working with similar language models.
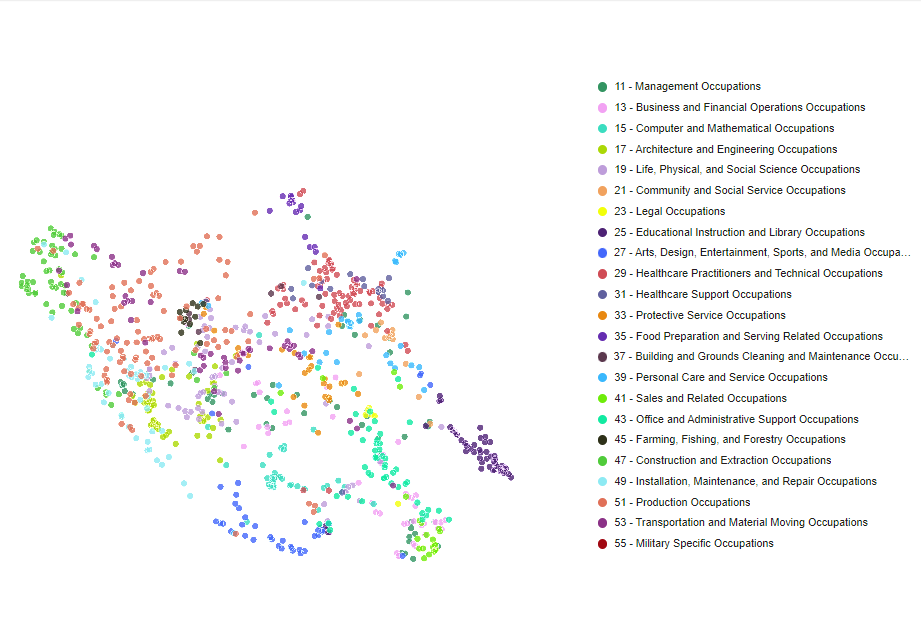
To conclude, the following visual shows in a three-dimensional space the distribution of O*NET occupations, based on semantic embeddings. Every point represents an O*NET occupation, and when hovering on it with the cursor more information on its counterpart in the ESCO classification are displayed, based on the crosswalk results. Try it yourself! You can turn around the cloud of points to better observe the different clusters, and points are coloured based on their SOC group. If you wish to focus on one SOC group, you can select it from the legend on the right-hand side.
The report The crosswalk between ESCO and O*NET provides more information on the methodology, mapping guidelines, and quality assurance activities adopted to build the mapping table. It can be downloaded at the link at the bottom of this webpage.
The ESCO-O*NET mapping table is available here. May you have any question, please contact us via email at EMPL-ESCO-SECRETARIAT@ec.europa.eu, and use our hashtag #ESCO_EU.
Learn more:

The crosswalk between ESCO and O*NET (Technical Report)
The Technical Report provides more information on this topic.
O*NET-ESCO Crosswalk Table
Download the official crosswalk.