About ESCO
ESCO is the European multilingual classification of Skills/Competences, Qualifications and Occupations. It identifies and categorises skills/competences and occupations relevant for the EU labour market and education and training area. The first version (v1.0) was published in July 2017 and provides descriptions of 2942 occupations and 13.485 skills translated into 27 languages and systematically shows the relations between the different concepts (occupations and skills).
ESCO has been developed in an open IT format, is available for use free of charge and can be accessed via the ESCO service platform.
For more information about ESCO’s structure and methodology, browse ESCOpedia.
The Commission has developed ESCO with the following aims:
- To improve the communication between the education and training sector and the EU labour market;
- To support occupational mobility in Europe;
- To make data more transparent and easily available for use by various stakeholders, such as public employment services, statistical organisations and education organisations;
- To facilitate the exchange of data between employers, education providers and job seekers irrespective of language or country;
- To support evidence-based policy making by enhancing the collection, comparison and dissemination of data in skills intelligence and statistical tools, and by enabling better analysis of skills supply and demand in real-time based on big data.
ESCO is continuously updated to reflect changes in the European labour market and in education and training. These changes are reflected in new versions of the ESCO classification. These are differentiated between minor and major:
- Minor versions: contain changes that do not affect the concept level (i.e. no concepts are added, no concepts are removed and the scope of the existing concepts is not changed). Minor releases refer to typos, adding or removing relations between concepts, making minor changes to the labels and the descriptions, etc. and do not require any update of mapping tables;
- Major versions: contain changes that affect either the concept level (i.e. concepts are added, concepts are removed and the scope of the existing concepts is changed) and/or the data model.
The first fully-fledged ESCO (major) version was ESCO v1.0. Already before this version (in order to manage the minor versions that would lead to the first major one), a versioning mechanism was put in place to keep track of changes in ESCO and manage its versions. In 2020, the Commission released four ESCO minor versions, i.e. v1.0.5 – v1.0.8 and commenced preparing the next ESCO major version, i.e. V1.2. More information about the different ESCO versions can be found here: https://ec.europa.eu/esco/portal/version.
Download ESCO
If you are looking for a file that includes all the relationships between occupations and skills in text, you will have to craft it yourself. In fact, as the relations between concepts are language independent, the files we provide show the relationships using uniquely the URIs. In order to create your own relations file in the language you desire, follow the instructions:
- Download the ESCO classification in the language you prefer
- Download the language independent files by selecting “language independent” when choosing the language
- Open both files in Excel
- Exploiting the URIs, use the VLOOKUP function in Excel to copy the preferred terms of the ESCO classification into the relations file.
ESCO structure and updates
Number codes may be problematic to update, especially when one skill is reallocated in another skill group within the hierarchy. On the other hand, URIs are never edited, which makes such information more reliable over ESCO versions.
For any specific request, the ESCO team is available to provide tailored tables.
ESCO is aligned with existing EU competency frameworks such as DigComp, EntreComp, LifeComp in the sense that ESCO’s transversal skills model was developed taking into account these different frameworks. We are further exploring ways to create the tangible interoperability (through metadata) between these different competency frameworks at EU level and ESCO.
Due to their nature, transversal skills should not be linked to any occupation. With the release of v1.1 most of the links have been removed, while the links that are still existing in the classification will be removed in future updates.
As for the digital skills (aligned with DigComp framework), they are generally not assigned to occupations, but some derogations are possible. These links are expected to be reviewed in future updates of the classification.
In general, we recommend using only the links between occupations and the skills mapped in the current Skills hierarchy.
Article 19 of the EURES Regulation and its Implementing Decisions adopted by the European Commission on 18 July 2018 provide for the use of ESCO with a view to developing an automated skills-based matching tool through the EURES portal. To enable successful implementation, Member States need to supply the job vacancies and CVs using ESCO codes defining occupations and skills. Member States have until August 2021 to map their national occupational classifications/national skills classifications to ESCO. Alternatively, they can decide to directly adopt ESCO.
By the end of 2020, the state of play was the following:
- 17 Member States were in the process of mapping occupations;
- 5 Member States were in the process of mapping skills;
- 4 Member States were in the process of adopting occupations;
- 4 Member States were in the process of adopting skills.
Currently the mapping tables are not available online but the Commission will publish them on the ESCO portal within the next months
The web-based service API is designed to support interoperable machine-to-machine interaction over the World Wide Web. It provides applications with access to the different versions of the ESCO classification. The functionalities of the ESCO Web Services API covers the majority of ESCO business cases. The ESCO Web Services API receives requests for information on concepts or terms and provides a response in a format specific to the sender of the request.
The ESCO Local API is the downloadable version of the ESCO API, which can be installed locally on a computer or server and thus provides local access to the ESCO API. Compared with the use of the ESCO API hosted by the Commission, the advantage of installing the ESCO API locally is an increased performance and the independence from the availability of the service provided by the Commission.
ESCO concepts are developed through the combination of several sources. National classifications, reports, job vacancies and research papers are constantly reviewed and analysed to identify skills and occupations belonging to the European labour market.
In the first development phase of ESCO, the Commission, with the collaboration of sectoral and occupational experts, analysed studies, national, regional and sectoral classifications, and relevant international classifications and standards. The rationale behind the use of existing sources was to build on the information of existing national and sectoral classifications, to ensure a good geographical coverage, reflect labour market reality and facilitate the mapping to national classifications.
For ESCO version 1.1, the Commission carried out desk research to identify the main trend for each sector of the labour market, with a special focus for green and IT topics, reviewed stakeholders’ feedback on this work and created new concepts. The latter were then validated by European sectoral associations, implementers, the ESCO Maintenance Committee (MAI), and the Member States Working Group (MSWG).
For the future updates, the Commission plans to include the use of data science and artificial intelligence, using data sources like CVs, job vacancies and qualifications from various training providers.
The development of the ESCO classification started in 2013. Together with stakeholders representing different sectors of economic activity, the Commission developed the occupations and the skills pillars of ESCO, focusing on labour market. To this end, they analysed a wide variety of existing sources, such as studies, job vacancies, national, regional and sectoral classifications, and relevant international classifications and standards.
The most important sources used were national occupation classifications from Member States (such as Berufenet, ROME, the Czech National System of Occupations and the UK NOS), classifications with a European scope (such as NACE and EurOccupations) and classifications with an international scope (such as ISCO). They were selected following different criteria including typology (classification, qualification standards, etc.), scope (European, national, etc.), quality and richness of the information.
To ensure that the ESCO terminology is fit for use in the education and training sector, the Commission and the stakeholders involved complemented these sources with information extracted from learning outcomes descriptions of qualifications.
The approach for developing occupational profiles varied depending on the sector. For some sectors of economic activity, expert groups (the Sectoral Reference Groups) developed the entire classification or, in some cases, worked on the basis of a draft provided by the Commission. For other sectors, the Commission developed a draft classification and submitted it for an online consultation with different stakeholders.
ESCO ensures that citizens can easily gather information about how occupations are regulated in each Member State when they search for a job. By providing a direct reference to the Regulated Professions Database, ESCO increases transparency regarding the legal requirements of these occupations.
Additionally, for occupations that are regulated at European level, ESCO provides a direct link to the Directive 2005/36/EC on the recognition of professional qualifications, as amended by the Directive 2013/55/EC.
Information on qualifications at European level is now displayed in Europass, and comes from databases of national qualifications reflecting the National Qualifications Frameworks that are owned and managed by the EU Member States.
One of ESCO's main missions is to build stronger bridges between the world of education and training and the world of work, in order to reduce skill mismatches and support the better functioning of the labour market. The vision behind ESCO is the provision of a common reference language that could support transparency, translation, comparison, identification and analysis of the content of a qualification, thus helping to indicate how those relate to the skills and occupations needed across occupations and sectors. ESCO does so in multiple ways.
- ESCO supports education and training systems in the shift to learning outcomes that serves better the labour market needs. Organisations that provide data on qualifications can use ESCO to annotate learning outcomes’ descriptions with skills terminology, thus integrating knowledge, skills and competence concepts. This helps learning institutions to express their learning outcomes in a way that facilitates the understanding of their qualifications by labour market actors and to attract learners from within and across borders. The Commission is conducting a pilot project in order to test automated linking of learning outcomes of qualifications with ESCO skills in different languages and has developed a dedicated IT tool to support national authorities in this exercise.
- ESCO skills and occupations can be used to provide jobseekers and learners with tailored suggestions of learning and training opportunities. Digital platforms can use ESCO to provide citizens with information on learning opportunities, suggest courses, develop tailor made training opportunities and recommend learning paths based on people’s skills. Career guidance providers can use ESCO to provide guidance services and recommend relevant training based on the skills set and career aspirations of an individual.
- ESCO can be used for the validation of informal and non-formal learning. The clear and detailed learning outcomes that are provided through ESCO can be used to identify, document, assess and certify the skills and experience that an individual has acquired through informal or non-formal learning.
Transversal knowledge, skills and competences are relevant to a broad range of occupations and economic sectors. They are often referred to as core, basic or soft skills and are the cornerstone for the personal development of a person. Within the skills pillar, transversal skills and competences are organised in a hierarchical structure with the following four headings:
- Thinking
- Application of knowledge
- Social interaction
- Attitudes and values
Both the concepts and the hierarchical structure of the transversal knowledge, skills and competences were developed based on the analysis of a wide range of existing national and sectoral classifications, the European Dictionary of Skills and Competences (DISCO) and other sources.
The skills pillar includes knowledge, skills and competences that are defined as follows:
Knowledge: The body of facts, principles, theories and practices that is related to a field of work or study. Knowledge is described as theoretical and/or factual, and is the outcome of the assimilation of information through learning.
Skill: The ability to apply knowledge and use know-how to complete tasks and solve problems. Skills are described as cognitive (involving the use of logical, intuitive and creative thinking) or practical (involving manual dexterity and the use of methods, materials, tools and instruments).
Competence: The proven ability to use knowledge, skills and personal, social and/or methodological abilities, in work or study situations, and in professional and personal development.
While sometimes used as synonyms, the scope of the terms “skill” and “competence” can be distinguished. “Skill” refers to the use of methods or instruments in a particular setting and in relation to defined tasks. “Competence” is broader and refers to the ability of a person, facing new situations and unforeseen challenges, to use and apply knowledge and skills in an independent and self-directed way. However, there is no distinction between skills and competences recorded in the ESCO skills pillar.
Alternative labels can be synonyms (words with similar or same meaning) but can also be spelling variants, declensions, abbreviations, etc. They are regularly used by the target group (jobseekers, employers, education institutions) to refer to concepts that are described in ESCO with the preferred term. It is a way to connect ESCO concepts to the real labour market.
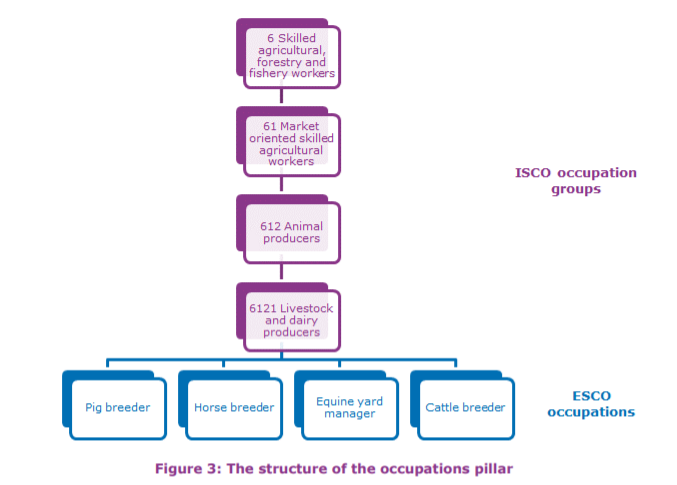
In ESCO, each occupation is mapped to exactly one ISCO-08 code. ISCO-08 can therefore be used as a hierarchical structure for the ESCO occupations pillar. ISCO-08 provides the top four levels for the occupations pillar. ESCO occupations are located at level 5 and lower.
Since ISCO is a statistical classification, its occupation groups do not overlap. Each ESCO occupation is therefore mapped to only one ISCO unit group. It follows from this structure, that ESCO occupation concepts can be equal to or narrower than ISCO unit groups, but not broader. The result is a strictly mono-hierarchical structure where each element at level 2 or lower has exactly one parent.
The ESCO occupations hierarchy has 4 levels:
ISCO level 1: major group. For example, Technicians and associate professionals (3)
ISCO level 2: sub-major group. For example, Information and communications technicians (35)
ISCO level 3: minor group. For example, Telecommunications and broadcasting technicians (352)
ISCO level 4: unit group. For example, Broadcasting and audiovisual technicians (3521)
Then below ESCO occupations can be found. For example, Audio-visual technician (3521.1)
Among the different ESCO occupations, there is sometimes a relation of broader or narrower term. For instance, Audio-visual technician (3521.1) is broader than Sound operator (3521.1.11).
ESCO was developed as a sector-independent classification, where occupations are mapped in groups depending on the activities that are needed to perform an occupation. Nevertheless, in the first phase of development of the classification, the Commission used NACE revision 2, the Statistical Classification of Economic Activities in the European Community, to divide the work for building ESCO occupations. The mappings between NACE and ESCO are not public.
More information about this topic can be found at the following link:
The active involvement of stakeholders and experts is crucial for the continuous improvement of ESCO. Key stakeholders include employers' organisations, trade unions, employment services, education institutions, training organisations, job portals, sectoral skills councils, statistical organisations and various government bodies, job boards, HR software developers, etc. There are many ways to provide feedback:
- Use the contact form on the ESCO website
- Write an email to EMPL-ESCO-SECRETARIAT@ec.europa.eu
Moreover, stakeholders can contribute to the further improvement of ESCO by providing:
- data already mapped to ESCO occupations and skills (such as job vacancies, CVs, qualifications, other taxonomies, etc.).
- data unmapped with ESCO but which reflect trends in the labour market (new occupations and skills)
- knowledge exchange on AI methodologies
- input on existing ESCO translations, in any of the provided languages
The Commission is publishing ESCO as Linked Open Data so that it can be connected to a range of external knowledge sources such as classification systems, controlled vocabularies and frameworks, databases, syntactical standards or tools that make use of ESCO to provide services.
Some of the classification systems and frameworks related to ESCO are:
- ISCO-08: Since each ESCO occupation is mapped to one ISCO-08 unit group, the two classifications are interoperable.
- National classifications: Some EU Member States have developed and currently use occupational classifications to deliver labour market services at national level. The Commission used several of these classifications as reference during the development of ESCO. Moreover, the EURES Regulation (EU) 2016/589 lays down, inter alia, principles and rules on cooperation between the Member States and the Commission regarding interoperability and automated matching between job vacancies and job applications and CVs in the EURES portal.
- Digital Competence Framework (DigComp): DigComp 2.0 provides a vocabulary of digital competences at European level. It is developed by the Commission’s Joint Research Center (JRC). DigComp 2.0 structures 21 competences in 6 competence areas. The Commission integrated the competences of DigComp into the ESCO list of digital transversal skills.
- European Qualifications Framework (EQF): Since 2019, the Commission has been conducting a pilot project for linking qualifications with ESCO skills with candidate Member States and international organisations in different phases. For the purpose of this pilot, the Commission developed a tool based on AI and machine learning, which is fully integrated with the ESCO skills and occupation pillars and makes also use of the ESCO API.
- International Standard Classification of Education, Fields of Education (ISCED-F): The 2903 ESCO knowledge concepts are allocated to the eighty detailed fields of education defined in the International Standard Classification of Education, Fields of Education (ISCED-F). This classification was adopted as the organising framework for the knowledge concepts within the ESCO Skills and Knowledge hierarchy.
- The Statistical Classification of Economic Activities in the European Community (NACE): The ESCO team created an internal mapping of occupations to NACE which will be published once it's reviewed and validated. Interoperability between ESCO and other international or EU standards is very valuable.
ESCO is continuously updated to reflect changes in the European labour market and in education and training. These changes need to be reflected in new versions of the ESCO classification and they include:
- Changes in the labour market
- Changes in curricula
- Changes in terminology
- Changes in the requirements of IT applications
These changes are reflected in new versions of the ESCO classification, differentiated between minor and major:
Minor versions contain changes that do not affect the concept level (i.e. no concepts are added or removed and the scope of the existing concepts is not changed). Minor releases refer to typos, adding or removing relations between concepts, making minor changes to the labels and the descriptions, etc. and do not require any update of mapping tables.
Major versions contain changes that affect either the concept level (i.e. concepts are added, concepts are removed or the scope of existing concepts is changed) and/or the data model.
Several minor versions have been released since the launch of ESCO and they contain small updates such as correction of typos, addition of translations, or improvements of the API services.
At the end of 2021, the first major update will take place with the release of version 1.1. It includes semantic additions to the classification, including new terms related to contemporary labour market trends. The plan in the future is to release major updates with a higher frequency, which will be possible thanks to the use of data science and artificial intelligence.
ESCO v1.1
During 2019 and 2020, the Commission analysed the feedback provided by ESCO stakeholders and implementers through different channels: the ESCO community fora, surveys, individual contacts with sectoral stakeholders. Based on the volume of inputs received and on the results of the analysis of this contribution, the update of the ESCO classification was structured in two major blocks:
- the content update exercise
- the targeted quality review of occupations and skills
The content update is structured in three work packages: the preparation phase, the research and analysis phase and the implementation phase (creation of new content and changes to existing occupations). The visual below summarises the main steps undertaken. A detailed explanation of each step is provided in section 5.1 of the annual report for 2020.
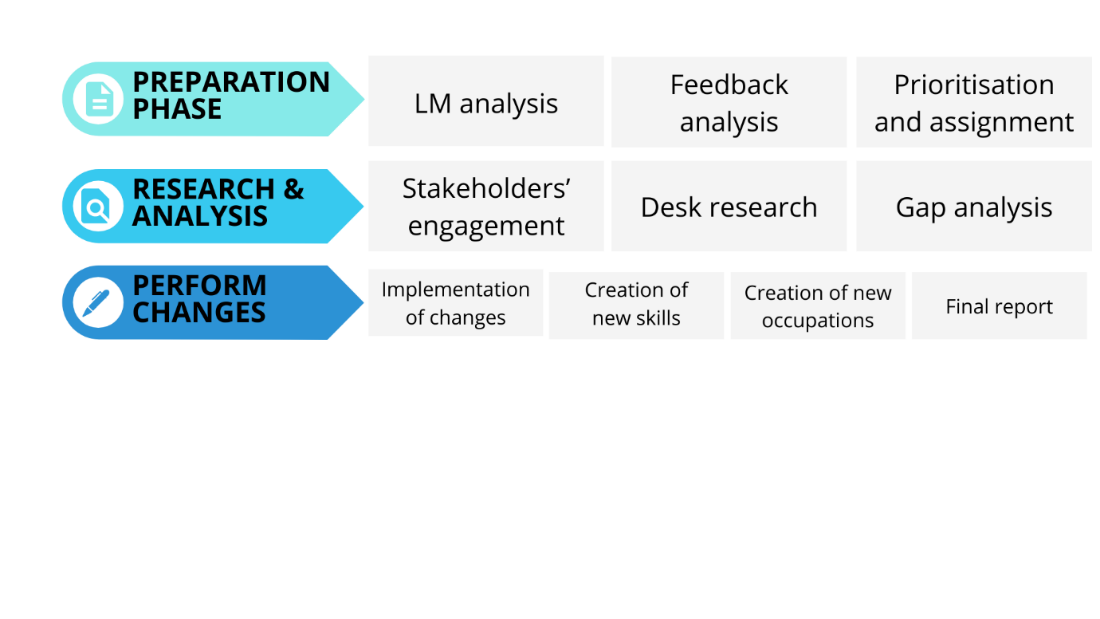
Addressing quality issues was retained as one of the key challenges for improving the usability of the classification. The Commission decided therefore to conduct a complete review of the occupations and skills pillars, which, combined to the feedback received from ESCO implementers, allowed to:
- identify duplicate and/or ambiguous concepts;
- correct typographic errors;
- reduce preferred terms that are too long;
- modify incorrect sentences;
- revise the action verbs used in terms (preferred or non-preferred);
- identify issues in the implementation of skills contextualisation;
- identify skills which are described as tasks or detailed activities;
- identify imbalances in the distribution of skills across occupations;
- adjust mappings of occupations to ISCO;
- address inconsistencies in the hierarchical structure of occupations (broader/narrower relations);
- modify the list of non-preferred terms;
- correct misallocations of skills in the skills hierarchy.
Terminological, conceptual and format guidelines have been evaluated to ensure they provide the necessary guidance to address the quality issues. Every modification to the classification has been quality assured by the Member States through targeted consultations.
For future versions of ESCO, the Commission is currently exploring how new technologies could support finding these quality issues or deviations from the guidelines and prevent them from occurring. This will make quality assurance of ESCO more efficient.
The semantic similarity approach was built using English, but we are working towards a multilingual model. We are currently collecting multilingual data and we welcome the sharing of data in European languages.
Job vacancies were only one of the sources to build links between skills and occupations. The primary source employed is feedback from experts, such as sectoral associations, European projects, etc. Other sources include national classifications, non-EU taxonomies, and qualifications.
Transversal skills are placed only in the Transversal skills hierarchy.
Links between transversal and non-transversal skills follow the broader/narrower relationship schema. You can consult them under each transversal skills in the Portal (for example here) or in the download files.
The methodology to identify obsolete skills aims at removing duplicate concepts from the ESCO taxonomy.
The ESCO team focused on the new transversal skills and compared them to existing ESCO skills using our semantic similarity models and human validation. More details can be found in the videos of ESCO v1.1 launch event.
The recordings of the presentations done during the launch webinar of ESCO v1.1 can be found here.
Implementation of ESCO: Use Cases
In accordance with the Commission Decision of 12 December 2011 on the reuse of Commission documents (2011/833/EU), the ESCO classification can be downloaded, used, reproduced and reused for any purpose and by any interested party free of charge. It may be linked with existing taxonomies or classifications for supplementing and mapping purposes. Any use is subject to the following conditions:
1) The use of ESCO shall be acknowledged by publishing the statement below:
- For services, tools and applications integrating totally or partially ESCO: "This service uses the ESCO classification of the European Commission."
- For other documents such as studies, analyses or reports making use of ESCO: "This publication uses the ESCO classification of the European Commission.
2) Any modified or adapted version of ESCO must be clearly indicated as such.
ESCO is intended to be a common language of skills and occupations, one of its goals being to ensure interoperability between services and to facilitate the exchange of information. For this reason, it is not recommended to modify the preferred terms and the descriptions of ESCO concepts, however, implementers have complete freedom of doing so, in order to meet their national/regional/local labour market needs. The information about modified concepts is very valuable for the improvement of ESCO, so implementers who do so are encouraged to share the eventual modifications.
ESCO is an important tool for Public Employment Services. It provides a standard terminology that helps to understand the information contained in job vacancies, CVs and qualifications and thus easily exchange labour market information. ESCO facilitates the design of job vacancies and job profiles in different languages. Finally, ESCO enables IT systems to transform a jobseeker’s work experience and qualifications into a likely set of skills and competences. Based on this, it is possible to match jobseekers to job vacancies or employers to potential recruits more accurately and transparently.
Employment Services around Europe are including ESCO in their systems, here’s a news article regarding Ireland’s implementation (https://ec.europa.eu/esco/portal/news/6e605a2e-0bcd-46f6-8cc6-5dce045ec407) and a testimonial video from Iceland (http://ec.europa.eu/avservices/video/player.cfm?ref=I162745).
ESCO will support the automated skills-based matching of the EURES service platform. EURES is the network of European employment services which aims to provide information, advice and recruitment and placement services for workers and employers.
Article 19 of the EURES Regulation and its Implementing Decisions adopted by the European Commission on 18 July 2018 provide for the use of a European classification of skills, competences and occupations (ESCO) with a view to developing an automated skills-based matching tool through the EURES portal. To enable successful implementation, Member States need to supply the job vacancies and CVs using ESCO codes defining occupations and skills. The deadline set for the mapping exercise is August 2021. Alternatively, Member States can decide to directly adopt ESCO.
The approaches used by the Member States to carry out the mapping vary. These could be:
- artificial intelligence tools;
- “human” approach, i.e. experts in the Member States carry out the mapping exercise manually;
- hybrid approach combing approaches one and two.
The panorama of ESCO implementers is wide and diverse. It includes European institutions, large companies, SMEs, start-ups, research bodies, universities, vocational training institutes, public and private employment services.
ESCO’s concepts and the relations between them can be understood by electronic systems. This allows different systems and platforms to use ESCO to suggest the most relevant jobs to jobseekers on the basis of their skills or the most relevant trainings to people who want to reskill or upskill.
The three main use cases for ESCO implementation are:
- Job matching and job searching ;
- Career learning and development management;
- Statistics and big data analysis of the labour market.
More information in this regard can be found at https://ec.europa.eu/esco/portal/howtouse/bfe2a816-f9dd-49df-a7d2-ec8fafcfce95
Examples of use cases can be found at https://ec.europa.eu/esco/portal/document/en/47b25dc1-145c-4f88-aa7c-fea929e47cf5
ESCO stakeholders directly contribute to advancing ESCO’s visibility and fitness for purpose in the labour market and the education and training sector.
ESCO stakeholders and implementers are encouraged to contact the Commission using the ESCO forum and/or the email address: EMPL-ESCO-SECRETARIAT@ec.europa.eu . The Commission is actively seeking to:
- understand how implementers are using ESCO in their applications and services;
- collect feedback in order to continuously improve ESCO;
- exchange knowledge on AI techniques and data science applications for maintaining and improving ESCO;
- create an ESCO community of practice centred around peer learning and knowledge sharing for the mutual benefit of all ESCO implementers.
ESCO can be used by developers as a building block for different types of applications that provide services such as auto complete, suggestion systems, job search algorithms and job matching algorithms.
The ESCO classification is published in SKOS-RDF and CSV formats, in order to enable users to integrate it into their applications and services. The files can be downloaded here.
The ESCO classification is composed of modules that contain elements such as occupations, knowledge, skills and competences, qualifications, and the International Standard Classification of Occupations (ISCO) hierarchy. When combined and interrelated, these modules make up the whole classification.
There are three main types of module:
- Core modules hold the actual ESCO concepts (occupations, skills, etc.) along with their Unique Resource Identifiers (URIs).
- Linking modules provide links between two or more modules, at least one of which is a core module. An example is the relation between occupations and skills.
- Supporting modules enrich the core modules with supporting classification schemes such as ISCO-08.
The Commission is offering access to ESCO through an Application Programming Interface (API), a tool for developers to access data and services in order to build all sorts of applications quickly and competently.
ESCO is published as Linked Open Data (LOD) so it can be easily reused and linked to other data sources. Using the Linked Open Data method helps users to:
- easily integrate data into their existing IT systems;
- link to other data;
- ensure that the data is well managed and quality-assured before publication;
- ensure that continuously updating the data doesn’t lead to high administrative costs.
ESCO and EURES synergies
The skills pillar of ESCO is composed of skills, knowledge concepts, language concepts and transversal skills. According to the EURES Regulation, EURES countries have to map their skill classifications to the ESCO skills or adopt the entire ESCO skills pillar.
ESCO and Member States mapping
EURES countries who are using the mapping platform since 10th February (release of ESCO v1.1), can keep their current mappings to ESCO v1.0 but they will also be able to map their national classification(s) to ESCO v1.1.
ESCO v1.1 will only be mandatory when the EURES coordination group gives a positive opinion. However, since ESCO v1.1 is necessary to keep pace with the evolution of the labour market, and also largely compatible with ESCO v1.0, it is recommended that EURES countries update the maps of their national classification(s) to the latest version of ESCO. This task will be facilitated with a delta of the changes (mostly additions of new concepts) between ESCO v1.0 and v1.1 provided by the Commission.
ESCO and AI
The Commission started a third pilot at the beginning of 2022 with the aim to improve the algorithm underlying the Linking learning outcomes with ESCO skills tool. Once the pilot is concluded and the robustness of the tool is satisfactory, the Commission will publish the tool via the ESCO portal.
We use sentence encoding using a pre-trained model finetuned on occupational data (ESCO, job vacancies, etc.). More specifically, we use the language representation model called BERT (Bidirectional Encoder Representations from Transformers).
ISCO updates
The ESCO team does not manage the translations of ISCO. This is done by Eurostat so the process is independent from ESCO. If you have feedback on ISCO translations, you can let us know at EMPL-ESCO-SECRETARIAT@ec.europa.eu and we will transfer your message.