The ESCO team is aware of the technical issues affecting some visuals on this page. We apologize for the inconvenience and are actively working to resolve the problem. If you have any additional comments, please use the contact form.
In part 1 we introduced the ESCO approach for connecting multilingual data to the ESCO occupations pillar. The methodology was illustrated by mapping concepts from national occupational classifications to ESCO concepts. In this news article we look at a different use-case and focus on mapping content such as job titles, work history descriptions or job advertisement descriptions to ESCO occupations.
Linking job titles and short phrases
The following table provides ESCO suggestions as obtained by the multilingual model for a number of input texts covering different languages and different input types.
The first six examples are more straightforward cases as is reflected in the scores; they mainly contain job title-like terminology. The Swedish (SV) example is showing that a 13-year-old looking for an assistant is likely referring to a nanny although not clearly described. The last two Dutch (NL) examples come from the domain of supporting elderly and indicate the link between the specific task and the information that is in the descriptions of the ESCO occupations. I.e. someone who is a companion ‘may do shopping activities as well as punctual transportation to doctor's appointments, etc’ while the more general ‘caring for an older person’ results in the occupation residential home older adult care worker.
In a previous article we discussed linking potentially new English alternative occupation labels to ESCO and presented an illustration for the marketing domain. The following figure shows a multilingual extension for this example. As before, the thickness of the line represents the strength of the association as computed from the model output.
Benchmark analysis
Recently, studies by Decorte et al. and Zbib et al. described approaches to compute job title similarities and perform job title normalisation. The authors highlight the limitations of a supervised method and present alternative approaches from representation learning. From our work on maintaining and updating ESCO, we also acknowledge the drawbacks of a purely supervised approach and the advantages that come with using representation learning. ESCO contains over 3,000 occupation concepts in 28 languages and is constantly getting updated, which makes creating and maintaining supervised data sets for mapping to ESCO occupations challenging.
Thanks to the study by Decorte et al., a benchmark dataset of English job titles together with their corresponding ESCO occupation became available. The test dataset as published by Decorte et al. contains 15,463 job titles from a broad range of industry sectors and all the records have one of the 2,675 corresponding ESCO leaf occupations linked to them. The benchmark results from Decorte et al. and Zbib et al. are summarised in the table below, together with the results from the ESCO multilingual model. ESCO results were obtained based on ESCO v1.0.7 and mapping to the English ESCO language variant.
For around 30%, 50% and 60% of the test examples, the correct ESCO occupation is in the top 1, 5 and 10, respectively. While having benchmark data sets is extremely valuable, Decorte et al. explain that there exists a significant amount of mislabelled cases in the test set, making these comparisons challenging. In addition, it is difficult to map to ESCO occupations by only taking the job title into account. Due to the granularity of the classification it is beneficial to include a description of tasks, skills or knowledge (if available) for mapping purposes.
Insights from the embedding space
In order to inspect how the multilingual model is representing text, we select a set of 34,904 unique job titles (covering 24 ESCO languages) from the EURES platform. For each of the job titles the embedding vector is computed and this data set is reduced to two dimensions by UMAP. In addition, the model is used to map the multilingual job titles to the English variant of ESCO and only the highest ranked ESCO occupation suggestion is kept. The figure below visualises the complete embedding space for all those job titles together with their level 2 ISCO code as derived from the predicted ESCO occupation.
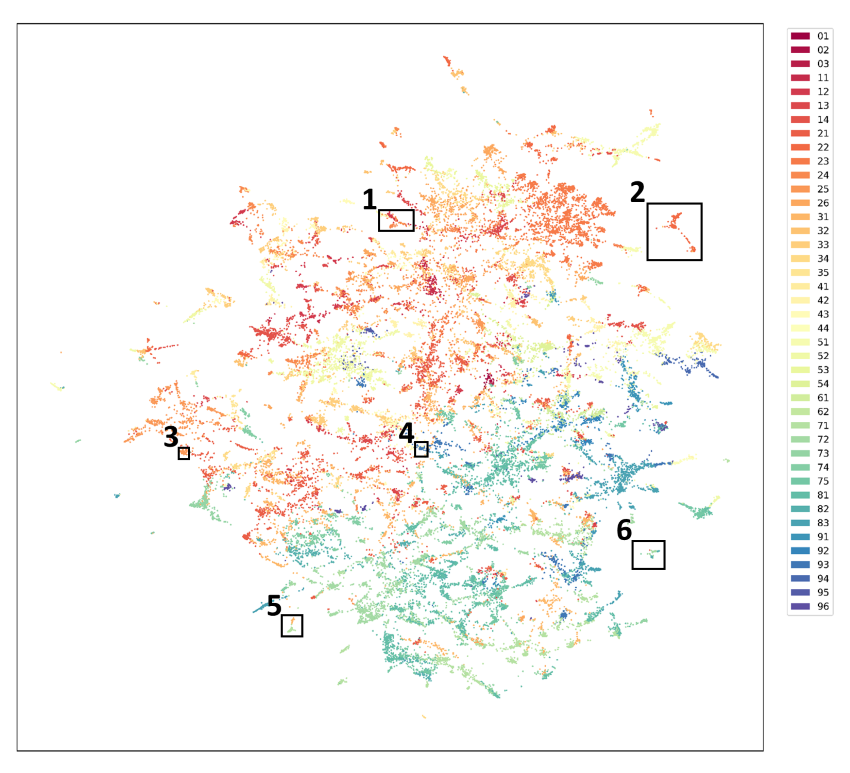
Six different areas are marked in this embedding space. For each of these areas a detailed figure that allows inspection of the original job titles (and English translations for ease of interpretation) is included in the report that can be found at the bottom of this page. Here, we restrict ourselves to area 1, which contains job titles from the field of human resources. In contrast to previous figure, the colour coding reflects the predicted ESCO occupation instead of ISCO groups.
From this visualisation it is clear that closely related job titles from different languages are close together in the embedding space. There does not seem to be a region with unrelated job titles from a single language clustered together. Also, seniority levels appear to be grouped together across the different languages. These results tend to suggest there is alignment between the different ESCO languages for the finetuned model.
What is the model looking for in free text?
The representation learning model is finetuned on multilingual ESCO skills, ESCO occupations, QDR qualifications and EURES online job advertisements without a filtering step. This means that the model had to learn from raw text (such as full descriptions of online job advertisements) the parts that were most relevant.
To understand to which extent this has happened we extracted six online job advertisements from EURES, corresponding to the following languages: Swedish, Norwegian, German, French, Lithuanian and Spanish. Panel (1) of the figure below shows the titles and descriptions for these online job advertisements and colours the parts of the descriptions that have the largest contribution to the predicted ESCO occupation suggestion (i.e. so-called key phrases). The underlying continuous score contributions are mapped to a discrete four-level scale (white, yellow, orange, red) ranging from minimal to maximal contribution.
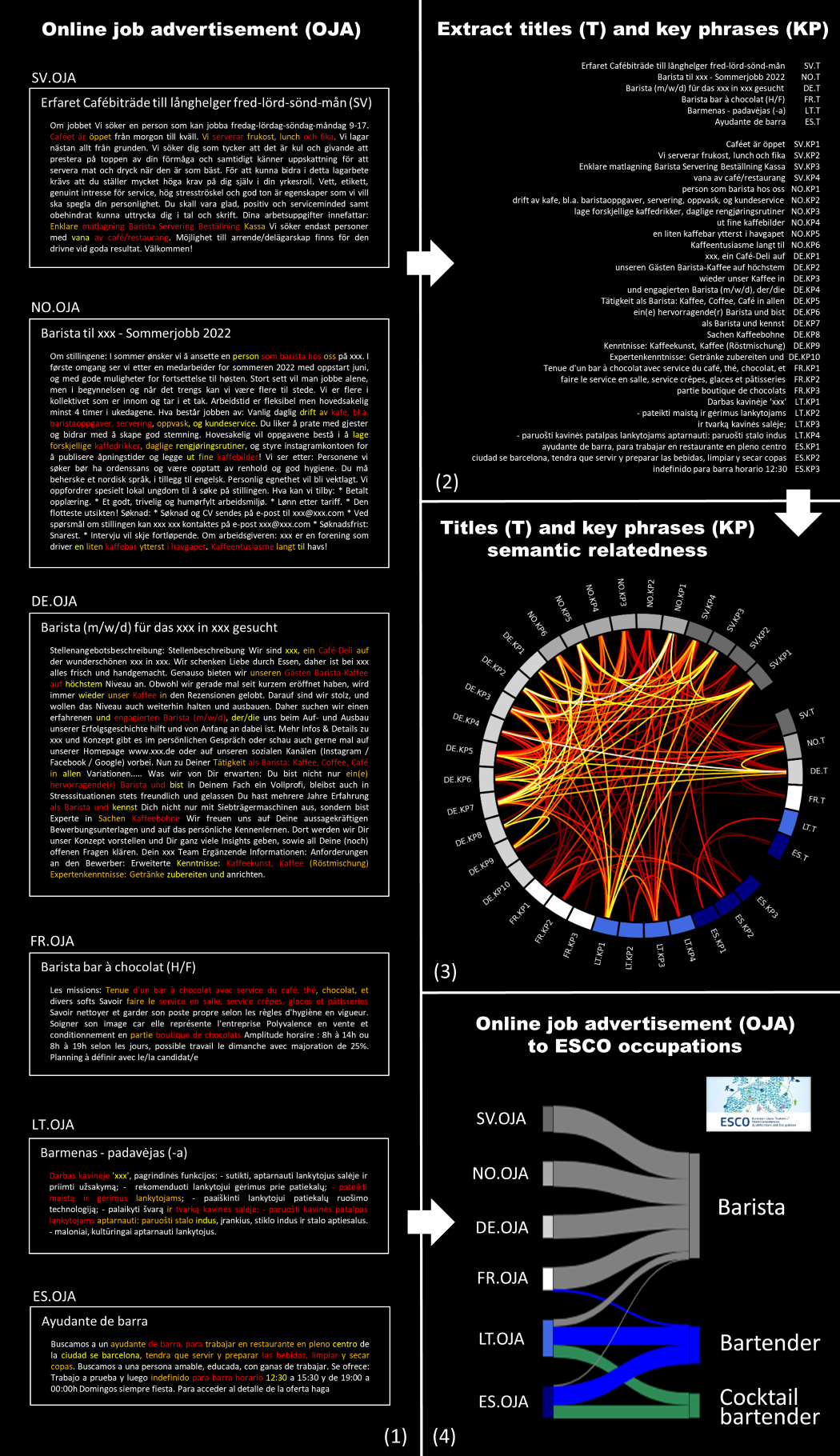
What is the model considering to be related phrases?
The key phrases from above, together with the online job advertisement titles, are listed in panel (2) and identifiers are added for ease of interpretation. The circle diagram in panel (3) visualises the semantic relatedness between all key phrases and the titles. The results show cross-lingual patterns originating from the alignment of the multilingual embedding space. A higher level of semantic relatedness exists between key phrases and titles for the Swedish, Norwegian, German and French online job advertisements, which are all for barista roles. The Lithuanian and Spanish online job advertisements are for a bartender position and show, for example, relations between the Lithuanian title and the Spanish key phrases. Finally, panel (4) presents the ESCO occupation suggestions by feeding complete online job advertisements to the model.
Summary
In two news articles the ESCO team explained about their approach for multilingual modelling to map text to the ESCO occupations pillar within the context of updating the classification. The approach was illustrated by mapping national occupational classifications, job titles, phrases from work history records and online job advertisements. Representation learning is used to finetune an XLM-RoBERTa model based on labour market data (ESCO, qualifications and online job advertisements) from 28 languages. The methodology is benchmarked for different use-cases and insights were provided to interpret the alignment of multilingual data in the embedding space.
The ESCO team is working on the continuous update of the multilingual model because of additional feedback coming from the task of maintaining ESCO and the availability of more labour market data. While the original training dataset consisted of tens of millions of records, the coverage for some languages was rather low at the time. Continuously more data became available which should have a substantial impact on the results for some low-resource languages. In addition, ESCO team aims to integrate the model in the mapping platform as a more powerful alternative compared to the existing TF-IDF approach and build APIs such that other stakeholders (e.g. Europass) can also take advantage of our expertise in this area.
If you are an ESCO implementer and want to share your feedback, please get in touch via email at EMPL-ESCO-SECRETARIAT@ec.europa.eu or use our hashtag #ESCO_EU.
